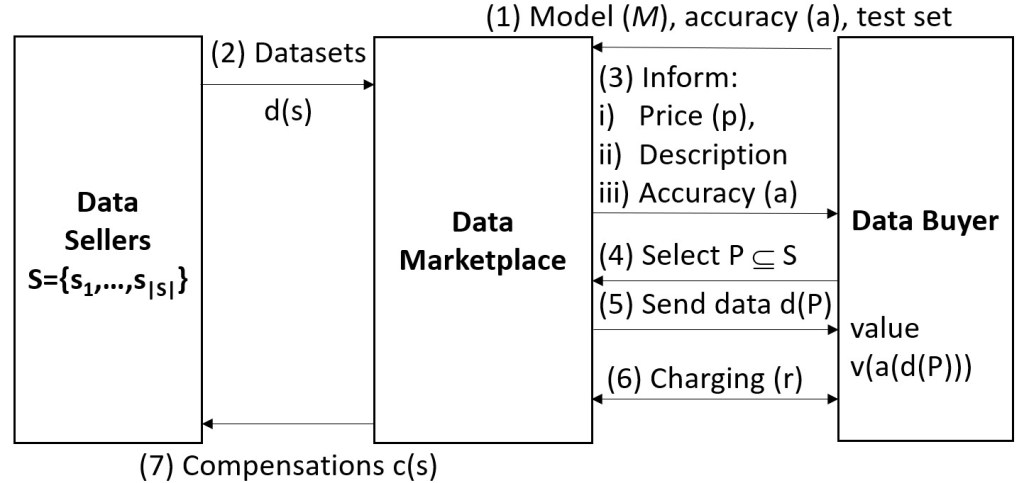
Bootstrapping data intermediation service providers (DISP) is far from straightforward. This is because of the chicken-and-egg problem stemming from Arrow’s information paradox. On the one hand, buyers have trouble deciding whether acquiring a dataset makes sense before they have tested it on their ML model. On the other hand, sharing a dataset in advance means effectively transferring it, which would likely ruin any posterior transaction.
In our paper «TBYB: a Practical Data Purchasing Algorithm for Real-World DMs«, we show that if a marketplace provides to potential buyers a measure of the performance of their models on individual datasets, then they can select which of them to buy with an efficacy that approximates that of knowing the performance of each possible combination of datasets offered by the DM. We call the resulting algorithm Try Before You Buy (TBYB) and demonstrate over synthetic and real-world datasets how TBYB can lead to near optimal data purchasing with only O(N) and O(N2) instead of O(2N) information and execution time.
This paper was presented in the ACM Data Economy workshop last December 2022 in Rome (See slides here). I do think that, for bootstrapping ML marketplaces, it is crucial such a preliminary data evaluation phase prior to buyers selecting which datasets to buy or gain access to. This can be easily implemented using sandboxes like the ones that Advaneo, Battlefin and other DMs already offer to play with outdated data samples of their datasets. However, in this case buyers would be able to find out relevant metrics of eligible datasets that would make it easier to choose among them. This concept was also developed in the Pimcity project (see WP3 deliverables, and this video), in other papers citing our work, and by other researchers such as Prof. Raúl Castro who proposed data escrows.
Not only does TBYB increase the profit of data buyers in data sourcing operations, but it also reduces the amount of data exchanged to train the models while it minimises the information disclosed to buyers in advance. As shown in the paper, consumers hoarding data could be significantly reduced if they are able to find out which datasets are more suitable for their ML task in advance. This, in the case of personal data, would impact privacy positively by limiting the disclosure of information to the minimum number of users needed for the task.
At IMDEA Networks, we are working on several tweaks to this algorithm that will eventually increase the efficiency and effectiveness of data procurement processes, always assumming that data marketplaces/escrows mediate data transactions and are able to execute code from potential data buyers to evaluate their data assets. We are also working towards making this process work in federated settings in the context of the project MLEDGE.

Deja un comentario