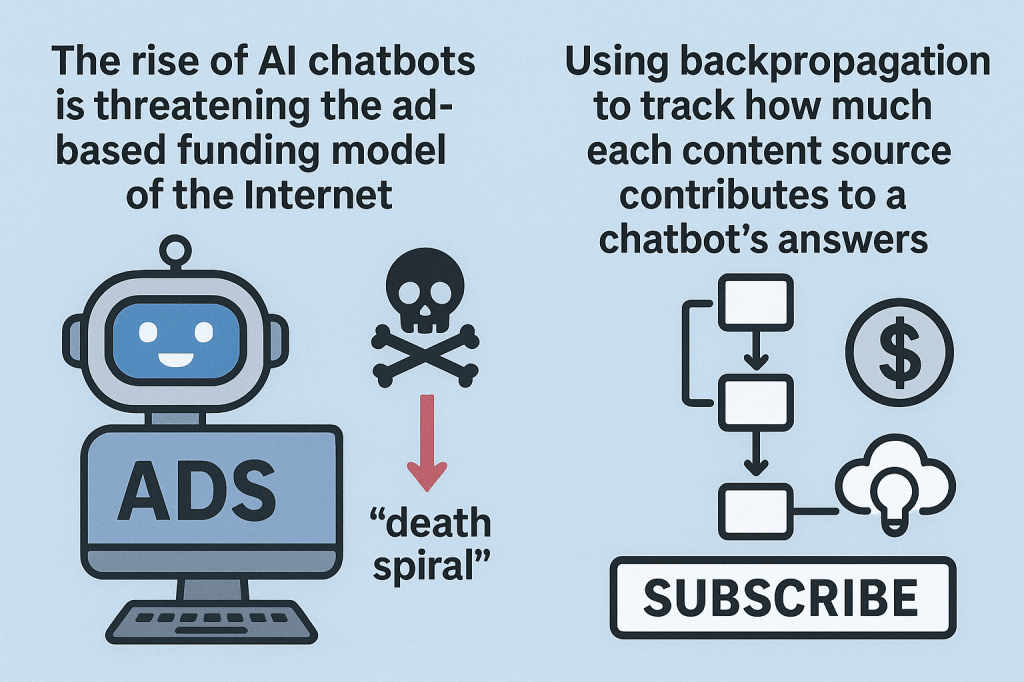
The rise of AI chatbots is threatening the ad-based funding model of the Internet, as users no longer need to visit websites that generate revenue from ads, but instead search for knowledge and content through AI chatbots. According to professor Pedro Domingos, this risks creating a “death spiral” where content providers disappear and AI loses its sources.
In a recent opinion article, he proposed using backpropagation, the algorithm underlying AI, to track how much each content source contributes to a chatbot’s answers. This would allow subscription-based or pay-per-answer models where revenue is fairly distributed to content providers, similar to Spotify’s system for music. Such a system could shift incentives away from clickbait toward high-quality content, ensuring sustainable funding for trusted sources and reshaping the internet economy.
The proposal revisits Jaron Lanier’s vision on people getting paid for data back in 2013, which was the motto of my PhD Thesis. Since then, the value of data has become an interesting research field for a number of reasons, and several lessons learnt can be applicable to this bold proposal to fix the economics of the Internet.
In my opinion, such a laudable objective should be a long term research direction, but it is far from becoming a reality for a number of reasons. From a technical perspective, it is not easy at all to build an scalable solution to calculate the contribution of training data/content in an answer of a genAI model. Backpropagation is the basic learning algorithm of neural networks and promotes or hides every parameter by adding a gradient to ensure the whole model response gradually adapts to the training data. However, it is not straightforward to connect backpropagation to source retribution. First, backpropagation is not needed for prediction. Second, it is arguable that odd training samples producing higher gradients are necessarily the most (or the least) valuable.
Other approaches in data valuation for ML pipelines have used approximations to the Shapley values of contributing data sources. However, the number of sources used by LLM is immense, and makes the problem of allocating intractable. A good start would be to acknowledge (and perhaps retribute) specific sources used by RAG, a technique to improve answers that most genAI models, and many AI chatbots use. There are already tools and studies that deal with this problem.
From an economic perspective, such a development would require a huge research effort and heavy processing. Not only should every search in a chatbot produce the result in the LLM, but a breakdown of the sources used to produce this result and how much they contributed to it, as well. And those sources should ideally include those seen during training time, during fine-tuning time, and in the context of a prompt. TechCos lack the incentives to lead and invest in solving this problem, as long as content/data exhaust is not here, and assuming they do not find a way to continue to use advertising in funding AI-chatbot search.
May regulations be helpful? Maybe. However, nascent AI and data regulations in the EU, including much less burdensome requests, are still controversial and heavily disputed by the industry. A regulatory process would be slow, and an effective enforcement will be difficult and will require duplicating efforts.
From a philosophical perspective, what is quality content? Why? Who decides? Based on what? How can we measure it?
On the contrary, I would expect TechCos to find a way to monetize AI chatbots. I can think of carefully adding advertisements to the responses, or prioritising relevant links shared with these responses according to the context. I think that a model similar to that applied in conventional keyword search can also be applicable to AI-based search, as well.
I welcome the article and I truly believe this is a scenario worth exploring, doing research and working for. Probably, this is one of the key topics to do research on on the Internet today. But I am afraid we are far from reaching a point were the Internet economy will pay back for the content based on its quality, whatever that means.
What do you think? Happy to read your comments.
Cover image generated by ChatGPT with the summary of the opinion article.

Deja un comentario