
The first prototype of my data pricing tool is ready! Are you a data owner willing to know the value of your assets? Are you a data consumer sizing a sourcing operation? The data pricing tool estimates the market price of a data asset based on its metadata. It’s user-friendly and simple:
1) Just type in a description of the data product, and some metadata such as volume metrics (# people, # companies, #records…), the time scope, the delivery methods, format, etc.
2) The data pricing tool can return an exportable list of similar datasets offered in public commercial data marketplaces, or by specific data providers. These can feed in-depth market analysis, provide more reference prices, or identify data sellers of a specific type of assets.

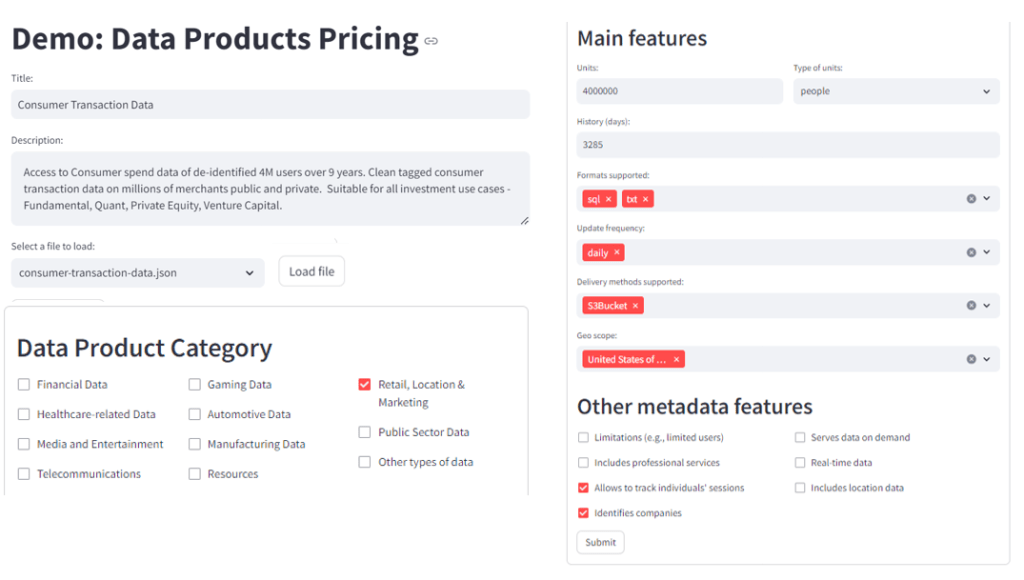
3) The tool can provide an estimation of the asset’s market price based on the prices observed in the market and based on ML models trained with data stemming from my prior research. As the figure below shows, the prototype provides SHAP explanations of the features affecting the prediction, including the relevant words in the description that appear to be driving it up (in green) and down (in red) the price of the asset.
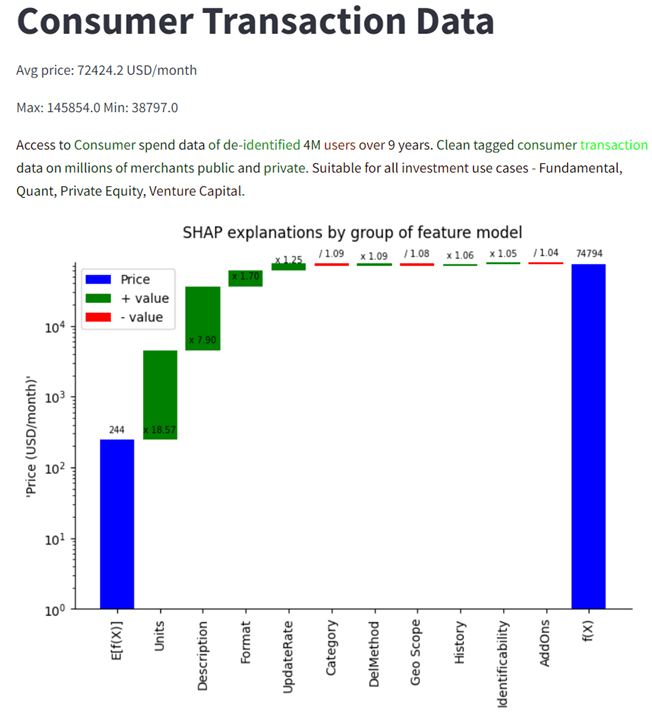
The SHAP explanation charts compare the average prediction for the training set – E[f(X)] – with the actual prediction for this product (f(X)). The tool can display SHAP explanations either by individual features – top-K most relevant features affecting the price -, or groups of features responding to the same aspect of the metadata. In the X-axis, the chart above shows the groups of features, and the bars reflect their impact on the asset price. Green bars show groups of features with multiplicative effects, whereas red bars show groups of features with divisive effects on the final prediction.
3) The tool can also display charts about the sensitivity of the predicted price to specific parameters, such as the volume of data supplied as the figure below shows:
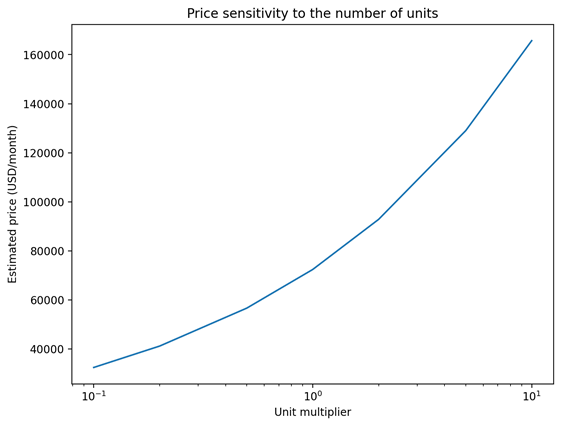
Even though the prototype is based on my previous research on understanding the price of data in commercial data marketplaces, it includes new functionalities and technical artifacts. First, it trains new more accurate models and embeds sentence transformers to make the tool more generalizable. Second, a comprehensive XAI layer, and an operational log were added to facilitate debugging, allow for audits, and eventually to pursue fairness, accountability, and transparency of this tool.
Still, there is huge work ahead to make this first version of the prototype more robust and commercially feasible, let alone issues related to the business model and to ensure trustworthy and ethical AI. Not only am I scraping more updated data, but I am also testing some ideas to drastically improve and streamline the data collection process, and to squeeze the data readily available. Moreover, I am looking forward to publishing more scientific papers on the topic.
See a demonstration video here! And feel free to contact me for more details.

Replica a AI Horizons @UC3M – Santiago Andrés Azcoitia Cancelar la respuesta